

近日,谷歌在博客上公开了高级研究科学家Konstantinos Bousmalis等人的成果——利用虚拟模拟器训练机器人抓握能力。研究人员设置了36种不同形状的物体,对一台协作机器人进行了超过25000次物理测试,成功把训练次数减少到了现实环境训练量的1/50。据了解,这个工具无需实际道具辅助,即使是现实世界不存在的物品,机器人都依靠经验能成功抓取。虽然目前该成果还停留在实验阶段,但考虑到仓储物流行业近年来对自动化技术需求的爆发性增长,以及AGV等机器人制造商的技术突破需求,这项抓握技术的落地值得期待。
虽然机器人正依靠它的计算机大脑和“钢筋铁骨”代替人类的某部分功能,但即便是最先进的机器人,它们现在也有一些难以逾越的技术鸿沟,比如一些涉及基本感官的能力——抓握。对于人类来说,几乎每个人都能通过学习更熟练、更稳健地完成复杂的抓取动作,但机器人不行。
这之中的难点主要有两个,一是感觉,二是经验。首先,让机器人完全模拟人手是不可行的,在装备上千个精密传感器的同时保证关节的灵活性,这在技术上暂时无法实现。其次,现在机器人虽然已经具备基础“学习”能力,但弊端也很突出:训练耗时久,训练对象固定,训练模式单一,即便它们能自主完成一些基本操作,整体水平也还是非常低的。
幸运的是,现在机器人多了一种新型训练方法:模拟(simulation)。利用现代的物理模拟、渲染技术和并行计算,在虚拟环境中模拟机器人互动方式是可行的。此外,模拟所得数据会自动生成注释,这对于实现正确的自主判断计算尤其重要。
那为什么大部分实验室仍在使用原始的模型道具呢?作为一项新技术,模拟训练所面临的一大挑战是无法完美捕捉现实环境,无论是视觉上的而还是物理上的,模拟环境与现实环境存在不小的差异。我们尝试过把模拟环境设计得更逼真,无论是设计更多仿真物理现象还是创建更多环境因素,但这都无法克服一个困难,即这个模拟器是基于强化学习设计的:机器学习算法越强大,机器人就越容易钻模拟器的“漏洞”,积累一些不可行的经验。
问题1:如何让机器人利用模拟,学会在现实环境中执行有用的任务?
解答1:通过现实中不可行的方式完成任务
问题2:如何让机器人利用模拟,学会在现实环境中执行有用的任务?
解答2:通过现实中不可行的方式完成任务
……
(如此循环,模拟器会一直认为“使用现实环境下无法进行的操作完成任务”是一个好解答)
模拟环境与现实环境的差异一般被称为“现实差距”(reality gap),这在机器人训练中起着微妙而重要的作用。“现实差距”最主要的构成因素是视觉感知:模拟图像需要进一步提高保真度、合成原图像纹理、调整长宽比,如果是运动的对象,它还要适应不可预知的多样性变化以弥合模拟器和现实环境的差距。正是由于这些原因,机器人在进行大多数任务时无法用人类的视觉图像去观察世界。
如今,计算机视觉领域已经涌现了一大批工具,可以帮助机器人适应不同像素、色彩、自由空间运动的对象,这些工具大多都使用了机器学习、深度学习的一些内容。而我们在这篇文章中要介绍的是如何使用域自适应学习方法,如机器学习,让机器人熟练抓取各种物理形状的对象。
进行模拟前,我们对如何让机器人抓取它“没见过”的物体有过讨论。谷歌大脑团队曾和一个发明家团体X's robotics合作过一个项目——让机器人从一张由单反相机拍摄的图片中辨认出各种对象,这个项目收集了大量现实数据资料,机器人训练次数高达几十万次,消耗了上千个小时。虽然现有技术可以提高训练效率,但考虑到现实中的物品会有维护、磨损和破裂,数据搜集工作量会显著提高。所以正如之前提到的,我们选择了一种更具吸引力的做法,用现成的模拟器让机器人学习基本技能,让它在虚拟世界中“感受”物体。通过模拟,机器人训练可以多线并行,学习效率大幅提高。
视频显示,实验共设置了36种不同形状的物体,研究人员把物体形状导入模拟器,之后利用渲染技术把图块渲染成真实图像。他们对一台协作机器人进行了超过25000次物理测试,成功把训练次数减少到了现实环境训练量的1/50。
如果训练目标是为了弥合现实差距,让基于视觉进行操作的机器人有更好的发挥,我们认为首先要回答这两个问题:
如何设计模拟条件,让神经网络认为这是真实的?
如何整合模拟经验和显示经验,让成果可以最大限度地转移到实际操作中?
这些问题即使对于机器人制造行业也是十分具有挑战性的,我们研究了一些基于计算机视觉技术抓取不同目标的机器人,并评估了其他模拟设计和经验整合方法。


在进行模拟时,我们要做出很多选择:模拟抓取的对象类型、外观动态是否随机、是否需要从模拟器提取更多经验来帮助抓取……抓取对象是模拟训练的重要组成部分,而作为仿真环境的组成部分,它们也必须能全方位地模拟现实。随机生成对象无疑是最合适、最简便的方法,但我们担心这不符合现实操作习惯,也不利于经验学习。于是之后我们考虑过使用ShapeNet这样的模型库,并训练了两个机器人进行测试。最后,我们发现还是随机生成对象表现更优,无论是训练经验还是现实经验,它的转化效果更好,学习效率也更高。



另一个需要考虑的问题是模拟现实环境,在这个问题中,我们还是采用了随机生成目标的方法。我们从两个角度评估随机环境,一是外观随机化(随机改变虚拟环境中可视化组件的纹理),二是动态随机化(随机改变目标的材质和摩擦系数)。在训练中,我们发现外观随机化几乎不对机器人产生影响,而动态随机化则会出现非常显著的效果。

最后,GraspGAN对我们机器人的训练效果有重要影响。在我们提出的方法之一中,我们利用提取的模拟图像的语义映射,即模拟图像中每个像素的描述,将其用于研究我们提出的域适应方法,以产生具有语义意义的实际样本。
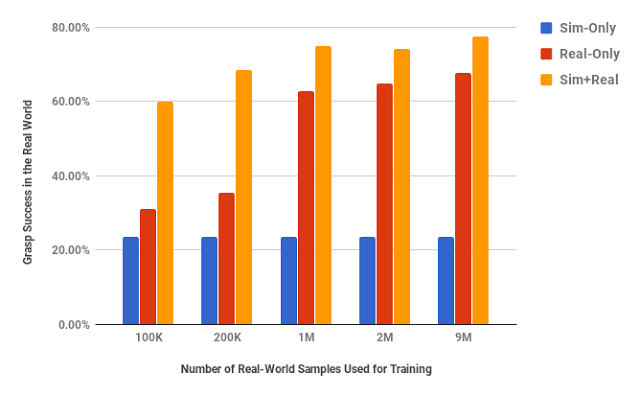
虽然这项研究仅针对机器人抓握训练,没有解决现实差距的所有问题,但我们相信整合现实经验和模拟数据,在模拟器中进行机器人训练是未来一个有吸引力的选择。更重要的是,我们已经广泛评估了不同数量现实经验样本对机器人性能提升产生的不同影响,以及模拟器和域自适应学习方法的不同设计选择。这种评估方法有望成为从业人员设计机器人的指南,帮助他尽快发现产品的优缺点。